Five Minute Facts About Packet Timing
By Doug Arnold
Why is IEEE 1588 so accurate? Two words: Hardware timestamping. That’s it, really! Let me explain. The Precision Time Protocol, PTP, defined by IEEE 1588-2008 works by exchanging messages between master clocks and slave clocks.
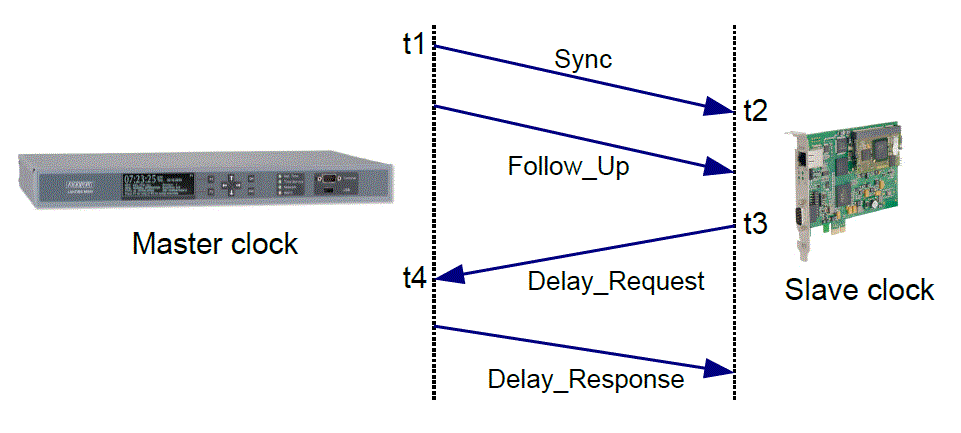
Figure 1. Sequence diagram showing the exchange of messages between a PTP master clock and a PTP slave clock. The departure and arrival times of the Sync and Delay_Request messages are saved as the four timestamps t1-t4. The Follow_Up and Delay_Response messages are used to transport the timestamps recorded at the master clock to the slave clock, so that it has the information needed to adjust its time.
At the end of these exchanges the slave clock has all four timestamps. So it can calculate the offset of it’s clock with respect to the master as
offset = (t2 + t3 – t1 – t4) /2
However, there is a catch. Isn’t there always? The equation assumes that the time it takes for messages to go from the master to the slave, the forward delay, is the same as the time it takes for messages to go from the slave to the master, the reverse delay. There is no problem if these delays are large, just so long as they are the same. Any difference in the forward and reverse delay results in an error in determining the difference between the master clock and the slave clock.
Why would the forward and reverse delays be different? Its mainly due to all of those pesky queues. There are queues in the routers, there are queues in the switches, there are even queues in the network stacks at the end devices. Usually messages spend minimal time in the queues, but sometimes they are waiting for a switch to finish up with other messages on the same port, or for an operating system to complete what it was doing so it can fetch a timestamp. In some cases the delay can be quite long, many microseconds, or even milliseconds. So obviously if this happens in the one direction, but not the other, then BAM! you’ve got a big time transfer error.
Since I already gave away the ending in the opening sentence, you know that this is solved with hardware timestamping. How this works is shown in the diagram below. When messages depart from or arrive at a network port, special hardware generates a timestamp from the local clock, usually in the media independent interface between the data link layer (MAC) and the physical layer (PHY). That removes the unpredictably slow response of the operating system and other software. Switches and routers which are PTP aware also timestamp PTP messages. One type of such devices, shown below, called a transparent clock works by updating PTP messages to correct for time spent in the device. Another type, called a boundary clock uses the PTP messages to set its own clock, then sends its time to PTP slaves which need it.
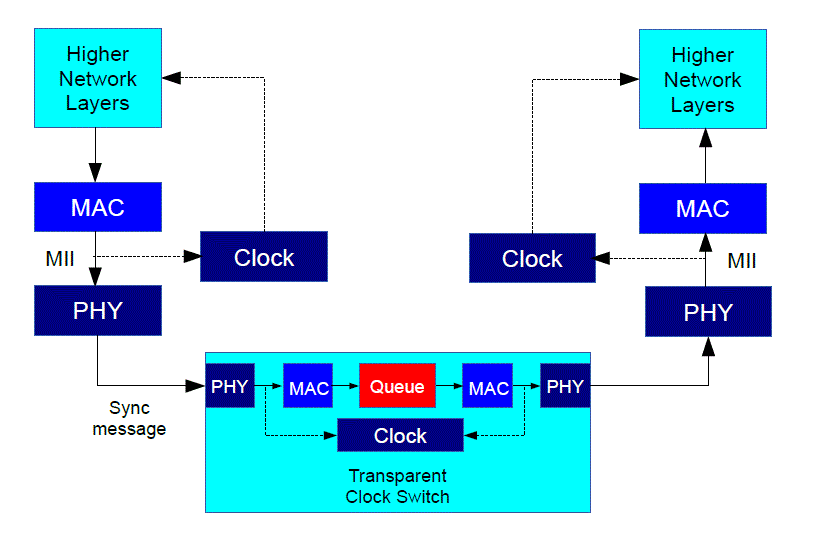
Figure 2. Diagram of hardware timestamping during the transport of a Sync messages. The Sync message triggers a timestamp at the local clocks of the PTP devices when it passes through the MII between the PHY and the MAC.
This delay measurement mechanism is know as the End-to-End delay measurement mechanism. As it turns out PTP has an alternative delay measurement mechanism known as the Peer-to-Peer mechanism. For a description of this approach to delay measurement see End-to-End Versus Peer-to-Peer.
If you have any questions about PTP or hardware timestamping, don’t hesitate to send me an email at doug.arnold@meinberg-usa.com, or visit our website at www.meinbergglobal.com.
Shouldn’t it be
offset = (t2 – t1 + t4 – t3)/2?
Perhaps you are thinking about the network delay. I start with:
t2 = t1 + delay – offset
t4 = t3 + delay + offset
adding equations I get:
delay = (t2-t1+t4-t3)/2
subtracting equations I get:
offset = (t2-t1-t4+t3)/2
Here I mean offset to be the slave clock – master clock at a given instant, and delay to mean the one way network delay, assumed to be the same in each direction.
OK. I see. Thanks.
First of all, THANKS! This is very good information! This blog is very practical. Working on 1588 and SyncE myslelf I can say that blogs like these are always good to keep fundamentals fresh. Would be interested in knowing if a discussion on best practices for validation/characterization would be added. Recommended components, HW timestamp accuracy vs overall solution accuracy (i.e. +stack, OS, application etc.). I think those would be great follow ups for the community. Or at least where could we find sources of information regarding these topics.
I have a question regarding the substract operation.
t2 = t1 + delay – offset
t4 = t3 + delay + offset
Shouldn’t the substraction yield:
t2 – t4 = t1 – t3 – (2 * offset) ?
Removing the negative:
-t2 + t4 = -t1 + t3 + (2 * offset).
Thus,
offset = (t4-t2 +t1-t3 )/2, and not offset = (t2-t1-t4+t3)/2.
Am I missing something?
Regards,
Javier
You are correct as long as the offset is understood to be the master clock time – the slave clock time. I took offset to be the opposite, i.e. slave clock time – master clock time. They only differ by a sign. IEEE 1588-2008 arbitrarily uses the slave time – master time definition consistent with what I posted in the blog.
That makes sense. Thanks.
I see on other sites in which they provide the following defintions
mean_path_delay = [(t4-t1) – (t3-t2)] /2
offset_from_master = [(t2 –t1) – mean_path_delay]
So:
mean_path_delay = [(t4-t1) – (t3-t2)] /2
= ( t4 -t1 -t3 + t2 ) / 2
offset_from_master = (t2 –t1) – ( t4 -t1 -t3 + t2 ) / 2
= 2t2 – 2t1 – t4 + t1 +t3 -t2
= t2 – t1 – t4 +t3
It also seems reasonable to me when i compare with what you provide
Good observation. There are multiple ways to order the timestamps.
I’m curious to find out what blog system you are utilizing? I’m having some minor security problems with my latest website and I would like to find something more safe. Do you have any suggestions?
WordPress
I am seeking the detail explanation of how the queuing is such a major issue in PTP based timed synchronized network. Also the figure Number 2 is not yet clear in understanding to me.
Thanks for such a great effort in making the blog. Its splendid!
Queues happen per egress interface in a switch or router… or a NIC.
The length of a queue varies in time – in terms of packets and in terms of bytes. Packets are variable length. If you want to minimize the adverse effect of queuing on time sync, the traditional approach is to implement priority queuing – so that time-sensitive packets always get trasmitted “first”.
Even that way, with a traditional implementation of priority queuing, once a miscellaneous packet “enters the meat grinder” = starts the process of its octets getting “shifted out”, you cannot preempt that packet. Technically it is no longer in the queue where you could “skip it”. It just gets transmitted until its end. (Canceling transmission and generating a CRC error is not an option.)
1500B at 1 Gbps takes 12 microseconds to transmit. Thus, your “band of timing uncertainty” is about that long, on a gigabit network interface.
HW PTP support in a switch can take care of this uncertainty = can correct for the queuing residence latency per packet, across the switch (there may be several partial forwarding matrices inside the switch chassis). Plus, physical link transmission delays also get corrected for.
hey,
I am getting network delay d = (t2-t1 + t4=t3)/2 as a negative value.
can network delay be negative and what does it mean?
Please help.
The network delay d=(t2-t1 + t4-t3)/2 should have a positive value. If it is negative, then it is an indication of some kind of technical problem. I have seen it, for example, when there was a bug in the timestamping unit of one of the nodes.
1) Can you please explain with network typologies where peer-to-peer and end and end transparent clock ?
2) Is it ordinary and boundary clock supports peer delay mechanism or is it applicable only for peer-to-peer transparent clock ?
3) how ptp will synchronize the network which having some ptp UN-aware nodes in middle ?
Hello Jayashankara,
1. Different topologies using Peer-to-peer and end-to-end delay mechanism are explained in this blog post: https://blog.meinbergglobal.com/2013/09/19/end-end-versus-peer-peer/
2. Yes, also ordinary and boundary clocks can support peer-to-peer.
3. The expected accuracy depends on the network asymmetry and hops in the link between a GM and slave, where PTP messages can be delayed. Please check this post about ptp networks without timing support: https://blog.meinbergglobal.com/2016/03/11/ptp-networks-without-timing-support/
Hello. I want to say thank you for writing this blog. It’s very helpful for me to understand IEEE 1588.
I have two questions about relationship between ‘network symmetry’ and ‘offset’. Firstly, if network is symmetry, ‘offset’ would be zero. Is that right? I think ‘network symmetry’ means that ‘Forward Delay’ is equal to ‘Reverse Delay’. Because ‘network symmetry’ means that Sync Message propagtion time is equal to Delay_Req Message propagation time.
Forward Delay = Delay + Offset = t2 – t1
Reverse Delay = Delay – Offset = t4 – t3
Offset = (Forward Delay – Reverse Delay) / 2
Then next question, does high asymmetry network means high offset? If that is so, I think offset correction is not difficult to handle than handling PDV. Because offset is relatively constant than PDV. But why there are many writings worried about network asymmetry?
Thanks for read my reply. I hope you to re-reply.
Hello Seungpyo-Han,
The problem with network asymmetry is that when the slave thinks that it calculates offset, it really calculates offset + asymmetry. And the slave has no way to know how much of the calculated offset is really the error of its clock, and how much is network asymmetry. So slaves will tend to steer their clock not to zero error, but to an error equal to the network asymmetry.
Doug
Thank you for the blog, useful stuff!
Understandably, PTP addresses accuracy requirements by hardware timestamping. What if the timestamping needs to take place on the application layer? PTP HW timestamping synchronizes the hardware (NIC) clock. How well is the accuracy preserved with the system clock?
Furthermore, what happens if the OS offers no PTP support?
Those are good and correct questions.
As you probably understand, HW timestamping is quite precise, based on the NIC’s hardware clock (also called the PHC). In a typical PTP slave (some commercial server machine), the PHC itself gets servoed by a PTP slave stack (software) to be loosely phase-locked to an upstream GM = that’s where it obtains its precise time. Alternatively, you could imagine hardware where the per-NIC PHC’s were in tight lock-step with some outside reference… (1PPS phase and some reference frequency) but that’s pretty much a pipe dream in the PC world. Unless maybe… unless you purchase an Oregano PTP NIC 🙂
Operating systems with “support for HW PTP” typically offer an API that allows you to get timestamps from the per-NIC PHC’s. You can get a timestamp upon external event (GPIO), or on the arrival of a packet, or “just now on demand”.
And yes, operating systems have a system-wide timebase of their own. That OS timebase runs in software = as a driver, paced by some hardware clock of the PC chipset. Originally, this was the PC AT interrupt timer, later replaced by the HPET and whatnot. These timers generate an IRQ once every = wake up the software driver say every 4 ms or every 1 ms. In addition to that, the CPU contains a counter called the TSC, ticking at some constant frequency (in the world of CPU’s that keep adjusting their clock rate based on load to save power). The TSC can be used to interpolate “what time it is right now” between the ticks of the sytem timebase counter…
So, the OS system timebase (software) can ask the PHC what time it is, perhaps periodically, and finely adjust its (OS timebase) frequency to remain close to lock-step with the PHC. There are tools for that in OS that cupport HW PHC’s.
As for OS that does NOT offer PTP support… that’s hard cheese if you only have “generic” hardware, albeit providing HW timestamping support. As of the time of this writing, Windows do not have support for HW timestamping and PTP.
If for some reason this is exactly what you need to do, you can purchase proprietary hardware that comes with proprietary drivers and a user-space DLL/API. Meinberg Funkuhren and Oregano are the right brands to investigate. Apart from the Oregano NIC, which can work as a versatile full HW PTP slave, you can get the same end result with a plethora of Meinberg receiver cards for GNSS, DCF77 and IRIG. If you take this route, your system timebase will be synchronized to the Meinberg hardware receiver, and your user-space apps can get timestamps either from the system using its generic API (e.g. GetSystemTimeAsFileTime() ) or via the Meinberg-proprietary API (from the proprietary HW clock via PCI-e or from the generic CPU TSC). The path via PCI-e has a higher latency and cost in terms of bus load. The access to CPU TSC takes a single CPU instruction, called rdtsc (plus some simple math to extract wall time).
Correction/update: Windows 10 and 11 and Server, have limited early support for HW timestamping by the NIC PHC since about 2019 or 2021, depending on what source of information you prefer to believe and how functional you expect the support to be. Recent versions of w32time also have support for PTP, in a particular configuration of its various features… appears to have a significant overlap with the PTP Enterprise Profile.
Hi,
My name is Shell Li and work as a Software Developer focusing on Synchronization technology in Sweden.
I found a lot of good article about PTP and sync in meinbergglobal, they are all very good resource to learn. But few of these articles have Chinese edition.
Chinese is my native language and good at English. Meanwhile I am studying the PTP at work. So I was wondering if I am allowed to translate some of the articles from meinbergglobal into Chinese in my blog. To learn for myself on one hand, on the other hand to introduce these good articles into China.
Thank you for your time!
Can I use some of your diagrams in an internal document to present to my management how we can standup PTP if I give credit to you for the work?
Yes. Good luck with your presentation.
Dear all,
I am trying to analyze an issue in a PTP network, we have a thirdparty switch set in TC P2P two steps that provides a path delay correction of around 600us, but some times the value achieves 1.2ms (the twice) to come back to 600us the next message.
From my point of view it is not acceptable to have soo much difference in the correction because it will impact the meanPathDelay, this correction shall be approximatively constant to have a meanPathDelay constant. Is it correct my thinking ?
I’ve reviewed a couple different switch models and I’ve learned early on (especially on the oldest models) that the actual correction value itself is not indicative of the resulting PTP time sync performance, as measured at the PTP slave 🙂 With a particular switch model, I’ve seen correction (i.e., PTP residence latency) of 20 ms or more! and this was considered perfectly normal by the switch vendor, and perfectly workable in practice = the slaves did accept it.
The reason for such high residence latencies is: PTP packets get special handling. In a particular Eth switch HW model, they may get diverted in MAC hardware to the switch CPU, and individually processed by the CPU – while all the normal Ethernet payload gets forwarded directly in the hardware. The switch MAC chip (subsystem) will assign a timestamp in the hardware to the ingress packet that it’s forwarding to the switch CPU, or that it has just accepted from the switch CPU for egress. The CPU-based processing can only be done in the two-step PTP style. For one-step processing, the CPU wouldn’t cut it = one-step needs to be implemented in pure hardware. In switches that process PTP in pure hardware, you will see correction values on the order of single-digit microseconds (a practical value, observed in a Gigabit-class switch) or possibly less.
Unsurprisingly, CPU-based processing imposes a cap on transactional throughput. Typically not a problem in P2P TC scenarios, as the switch CPU is designed strong enough to handle a PDelay transaction once per second on every port (in each direction = times two) and an Announce + Sync + FollowUp once a second multicast to all ports. P2P scales well. What does *not* scale well ie E2E, with a special sting hidden in the multicast (L2) flavour.
Hi,
I suppose there is a mistake in the following equations:
t2 = t1 + delay – offset
t4 = t3 + delay + offset
After subtraction we get offset = (t4 -t2 -t3 +t1)/2, instead of (t2-t1+t3-t4)/2.
Hence the equations must be as follows:
t2 = t1 + delay + offset
t4 = t3 + delay – offset
Please correct me if I am wrong.
Whether the original post is correct or your version depends on whether you define offset as slave time – master time, or the other way around. The convention in the post is the one used in IEEE 1588.
Okay, got your point.
Thank you for your response. Its a nice article on PTP and its internals.
littel Typ in description “Figure 1.” it must be “slave clock” not “save clock”
Thanks for your very careful reading!
Regards,
Andreja
Are the offset equation purely deterministic equations or there is a need to look at multiple packets and find a good estimation of the offset?
The equations for clock offset and propagation delay assume that the propagation delay for the sync message and the delay request message is the same. Any difference due to queuing delay differences in switches translates into error in both offset and delay calculations. So to get accurate result in the presence of queuing it is best to use some kind of lucky packet filter on the front end of the slave port PLL. If all of the switches are BCs or TCs then this will not be necessary, since queuing noise is removed by PTP aware switches. Not also, that when peer delay is used, the switches are necessarily BCs or TCs.
The simple math presented here provides a “per PTP transaction” estimate. Arguably, this is kind of coarse. In practical topologies, you will observe variations of this “per transaction” offset estimate, i.e. jitter. How much of it, that depends on the real-world quality of the corrections of the PTP-aware hardware involved. There are always some residues, at least a bit of “quantising noise” around the temporal resolution of your timestamping units, i.e. single-digit nanoseconds as of the time of this writing – but often more, depending on the particular Ethernet switches involved, the model of NIC chips in your PTP slave etc. (early NIC’s with HW timestamping were not as precise as later generations).
What typically follows is a local oscillator, giving the nominal clock frequency to a local hardware timebase (implemented by a cascade of counters). This local oscillator, based on a quartz crystal, is steered by the adjustment error = by your jittery PTP offset. Yes indeed, you’re right, there will be a low-pass filter in the PLL feedback loop, possibly implemented in the digital domain = as a moving average. The Tau = your loop filter’s response time constant can be in the range from a couple seconds for a poor man’s VCXO up to dozens of minutes for a top notch OCXO. The details of those PLL/VCXO adjustment algorithms are among the sweetest secrets of time sync vendors’ R&D departments 🙂